




Tensor Processing Units: Both History and Applications
Google announced its Tensor Processing Units (TPU for short), in May 2016 as a Custom made Application Specific Integrated Circuits for Machine Learning. It’s built to be compatible with Google’s Tensorflow project, which is an open source software library for machine learning across a range of tasks. It can build and train neural networks to detect and deal cipher correlation, in a manner that’s lucid to human patterns and reasoning. Some of it’s widely publicized uses include:
RANK BRAIN — Machine learning AI system that powers Google search engine.
GOOGLE MAPS — Where used to improve the accuracy of results. Example: Reading Street numbers
ALPHA GO — Program developed by Deepmind to play Go.
To really understand how exciting TPUs are, however, we need a little bit of background, and which is why I’m going to give you a brief overview of both CPUs and GPUs, both of which are types of electronic circuitry used in computer systems.
 Intel Core i9 X-Series CPU/Processor
Intel Core i9 X-Series CPU/Processor
Central Processing Units (CPU for short), are electronics circuitry used in a computer system that carries out the instructions of a computer program by performing basic Arithmetic, Logical control, and Input-Output operations. They came into widespread use in the 1950s and 1960s and due to their configurations; namely limited storage capabilities and at least initial relative flexibility, they were suited to Serial and Linear, ie: to step by step processes.
 Nvidia Tegra 4 GPU
Nvidia Tegra 4 GPU
Graphics Processing Units (GPU for short) is a more specialized electronic circuit designed to rapidly manipulate and alter memory to accelerate the creation and display images. They are used for texture mapping; which is very useful for video games and to solve embarrassingly parallel problems with ease. And in 2005, GPGUs begin to be used in training convolutional neural networks. And the key point here is, they were used to you run slightly more heavy duties in terms of both spatial and energy parallel processing.
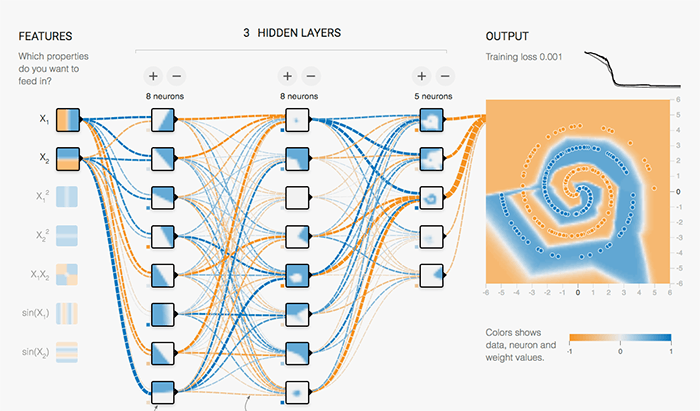 Training Neural Networks on Google Cloud Playground
Training Neural Networks on Google Cloud Playground
As the machine learning and neural networks turned out to be more popular the need for or something that could handle incredibly large amounts of data and complex processes and to do both of those things quickly arose. With large neural networks sources, systems inspired by biological structures and in particular, the brain learn; and to say they progressively improve performance to do tasks. Generally by considering examples during the training period in which both the input and output are provided to the system. After it has been configured to a sufficient degree of accuracy through these supervised methods, all the input is given to the system which then provides its own output to be compared to the expected results. In artificial neural networks that are based on a collection of connected neurons that turns to portray the axons in the Brain. These node like structures generally have an internal state that is represented by real numbers typically 0 that you can think of it as OFF and 1 which is ON. This activation of a neuron is handled by an activation function which takes information from the upstream neuron and determines whether or not it exceeds a threshold like a biological action potential in the cells. Only if the aggregate information passes the threshold the information be passed down the stream. Each connection or synapse between the neurons can transmit signals to another neuron. However, depending on the determined weight or relative importance of this link only a certain percentage of the information will be sent down the stream. This weight is configured to improve the accuracy as the learning proceeds to a state called back propagation, which will then increase or decrease the strength of the signal that sends it’s downwards. And typically the neurons and synapses are organized in layers so different layers may perform different kinds of transformations on their inputs and the signals traverse from the first of input layer to the last of output layer possibly after terracing layers multiple times.
 Tensor Processing Unit 2.0
Tensor Processing Unit 2.0
This is actually where the Tensor Processing Units (TPU for short) comes in and this is what it was built for. TPUs implement a process called quantization, which uses an 8-bit integer to approximate a value between a preset minimum and maximum value. So it comprises of a range of values into a single one. so this is ideal in case of spacial optimization and reduces energy consumption. Complex Instruction Set Computing (or CISC for short) designed for the process of implementing high-level instructions. They run more complex tasks with these instructions. This is in the post of Reduced Instruction Set Computing (or RISC for short) designs implemented in most GPUs and CPUs. With RISC, the focus is to define simple instructions and to execute them as quickly as possible. Typical RISC processors provide instructions for simple calculations such as multiplying for adding numbers and hence are called as scalar processors, as they perform single or Scalar operation with each instruction. In contrast, TPUs have a Matrix Processor, which processes hundreds of thousands of matrix operations in a single clock cycle, and you can think of it as printing an entire document at once rather than word by word or line by line. There was actually a second generation of TPUs released in May of 2018; called as Cloud TPUs and they can both run and train neural networks. They include a custom network that allows the construction of machine learning, could include supercomputers which are called TPUpods.
 Cloud TPU Pods
Cloud TPU Pods
So this is incredibly exciting, but the question occurs; Where do we go next…? And obviously, I don’t have the answers. But, I do want to draw your attention towards some emerging patterns and their associated questions. As we have seen the progression from CPUs to GPUs and to TPUs, there has been a trend towards favoring: parallelization of processes, extending of storage spaces and increase in complexity and interdependence of pieces, both form, and function. So the questions that can be arised from the above patterns include those of implementation.
How can we implement TPUs in the best possible way…? How will they change our strategies of approach towards a particular problem…?
Now we start prioritizing Brute Force Approach, not that we have unlimited speed and storage space over, we continue to seek efficiency. At what point does one of those things become more valuable than the other. And TPUs engage with Moore’s Law; which I would let you look at more later if you want;
As Time and Technology precede, we tend to pack more and more information and more and structures inside a smaller and smaller space (In my words).
So, that’s like an exponential growth curve. And the question is; What is the limit to this…? Do we even properly understand what TPUs can do…? And, I would argue that we don’t, because we don’t know what the Brain does either, and neural networks are modeled on the brain and TPUs are modeled to work with neural networks.